Real World Deep Neural Network Examples
Introduction
After the last lesson, I hope you have got the primer of how Deep Learning and TensorFlow work. In this lesson, we will use some real-life Deep Learning networks, that are used in production for many different applications. The work needed behind creating and training these models is a lot, and you simply cannot go through all the details of each model in this single lesson. So we will focus more on the application and specialty of these models. We will only load the pre-trained models, and run them on some of our custom images.
Traditional Neural Networks
AlexNET
AlexNet CNN is probably one of the simplest methods to approach understanding deep learning concepts and techniques. This is why this network is the first one I want to introduce to all of you. AlexNet is not a complicated architecture when it is compared with some state-of-the-art CNN architectures that have emerged in more recent years.
Note: We will create a complete Keras pipeline for only this section. As most of the pipelines in Keras are almost the same, the later discussion will only go through the model architecture definition function.
Maybe you are already tired to see the fashion MNIST and IRIS dataset. That’s why we will use a different dataset in this lesson, CIFAR-10 dataset. This can also be found inside the datasets submodule of TensorFlow.
But first things first, we import all the modules we need for the pipeline:
| |
And now we load the training set. CIFAR-10 is a dataset of images of different animals just like the MNIST dataset. But the dataset is larger than MNIST. It contains 50 thousand images for the training set and 10 thousand images for the test set. We will divide the training dataset into two again: for training and validation. The first five thousand images will be for validation, and the later ones will be for training. We can easily do this using NumPy slicing.
| |
The most convenient way to train a dataset is through a TensorFlow dataset object as discussed in a previous lesson. So we will convert these NumPy arrays into a TensorFlow dataset using from_tensor_slices method of the Dataset submodule. Finally, we can see the number of images in each division using the cardinality method.
| |
The output is:
| |
Let us take a look at some of the images using matplotlib. We will use the take method to randomly sample some images and display them in subplots.
| |

Now comes the preprocessing part. The pixel values of the images are now in the range of 0-255. We need to convert it into a range of -1 to 1. Thanks to the convenience of the Dataset submodule, you can use the per_image_standardization method on the dataset. After resizing it to the model’s desired shape, we shuffle the data and apply a batch size of 32 to train the model.
| |
The model architecture contains a set of Convolution-BatchNormalization-MaxPool sets first. Then finally the data is flattened and two fully connected layers of 4096 units are used. As the output is the probability of 10 classes, the final fully connected layer will have 10 units only.
| |
For training the model, we can use both Categorical Crossentropy or Sparse Categorical CrossEntropy as the loss function. But using only Categorical cross-entropy will lead us to another step (converting the labels to one-hot encoding). So we will use the sparse one as loss function. The optimizer is the Stochastic Gradient Descent algorithm.
| |
We can now start the training with the fit method on the model.
| |
Note: This will take a lot of time depending on the machine you are running on. Also if you are low on available memory in your computer, your system may get stuck. Alternatively, you can run a notebook on Google Colab or Kaggle using GPU for free.
To evaluate the model, we can run the evaluate method on the test_ds set.
| |
| |
So the mean accuracy on the test set is 86.26%. That is actually good for this old neural network created in 2012.
You Only Look Once (YOLO)
The first model we will try is the YOLO object detection model. This is a model where you can give the image and it will detect a lot of objects for you. The first Yolo model (Yolo V1) could detect 80 real-world objects. YOLO is a state-of-the-art, real-time object detection system. On a Pascal Titan X, it processes images at 30 FPS and has an mAP of 57.9% on COCO test-dev.
The major advantage of YOLO is that it is very fast. Unlike other Classifier based neural networks, YOLO applies image classification on multiple regions in parallel with the help of GPU, and if an object is detected, it uses an object classifier to classify it.
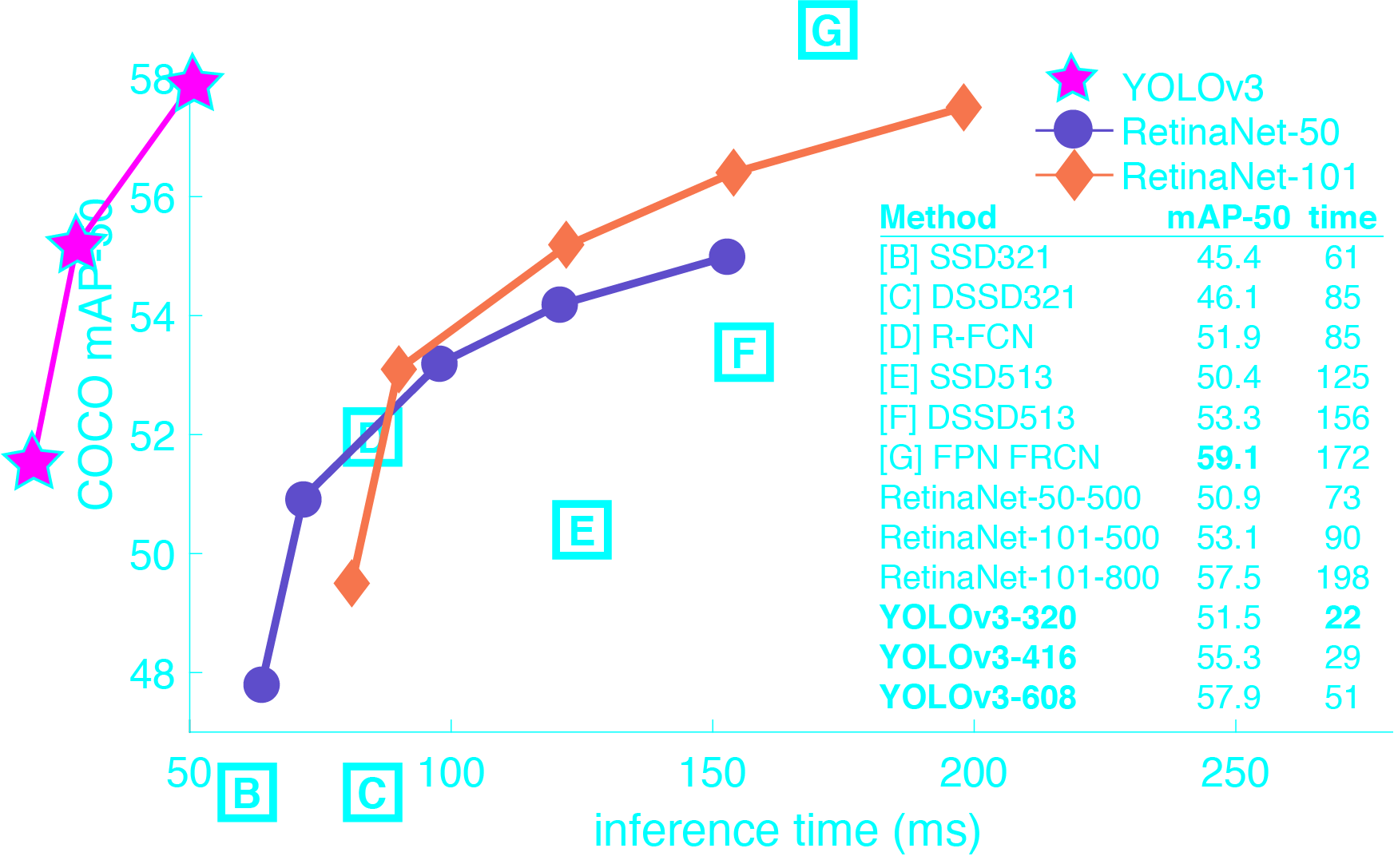
There is a lot of implementation out there for YOLO. The original code for darknet can be used with OpenCV’s DNN module. But we will use a much simpler version by Anushka Dhiman. Although I have no affiliation with any of the persons’ repositories, I only select these because I found these the easiest to use. Her repository supports TensorFlow 2 and is up-to-date with Yolo v3. Let us first download the code and set up the environment.
| |
There are two YOLO models: yolov3 is the large model with the highest accuracy, and yolov3-tiny is designed to have higher FPS but a little less accuracy. We will try the regular yolov3. To use this on an image, there is a function names detect_image in the utils file. All we need to do is load the model with Load_Yolo_model and then use that function on the image.
| |
If you want to run the object detection on a video file, then you can use detect_video function.
| |
Finally, you can also use your primary webcam to apply object detection live.
| |
Let us now get a little deep into the implementation of the neural network. The model architecture in python is given below. Yes, it is huge. Most of the established deep learning networks are like this.
| |
Training the model will literally take days if you are planing are planning to train it on a large dataset like Microsoft COCO. There is a total of 62001757 parameters you need to pass through when feeding forward.
VGG Network
Named after Visual Geometry Group, Oxford University, the VGG network is based on repeatable blocks named VGG-blocks. These are groups of convolutional layers that use small filters and max pooling layers. Assuming that you already can readout a code and understand the neural network architecture, I am giving the python code for VGG_Block without describing it:
| |
You can use VGG blocks in any of your models because they are so simple and effective. In the below example the first two blocks have two convolutional layers with 64 and 128 filters respectively, the third block has four convolutional layers with 256 filters. This is a common usage of VGG blocks where the number of filters is increased with the depth of the model.
| |
The summary of the model is like this:
| |
After building the model, all the other works are pretty much the same. You compile the model with an optimizer, fix learning_rate, batch_size, epochs and other hyperparameters. Then fit the model on a dataset.
Inception Model
The inception model was first introduced to the GoogLeNet model back in the 2015 paper. You will be amazed it is still one of the most powerful neural networks out there. Like the VGG model, the inception model also has an inception module which is a block of parallel convolutional layers with different sized filters and a and 3×3 max-pooling layer. The results of all the layers are then concatenated into one layer.
| |
The function takes the previous layer as input and the kernels for the 3 convolutional layers in an inception module. The concatenated form of these 3 layers is then returned to you for further use.
The rest are the same as VGG network. You need to create a model with multiple linear inception modules in it. As you can see, the model building and summary are just boilerplate codes. The interesting part is the network module layer. This is true for most of the models we will see today.
Residual Model
Residual Model or ResNET is also developed by Google which uses loopback residual blocks. A residual block contains two convolutional layers with the same number of kernels and a small filter size where the output of the second layer is added with the input to the first layer.
| |
Keep in mind that you need to be careful about the number of filters in the input and output layer. If they do not match, you will most like get an error. The residual network uses one kind of skip connection, which is the unique part of this architecture. In many cases, a lot of primitive features in the network are lost if the model is too deep. Residual network solves this problem with skip connection. The later layers of the model can select them if it needs the output of the layer that is closer to the image, or the previous layer.
Generative Adversarial networks
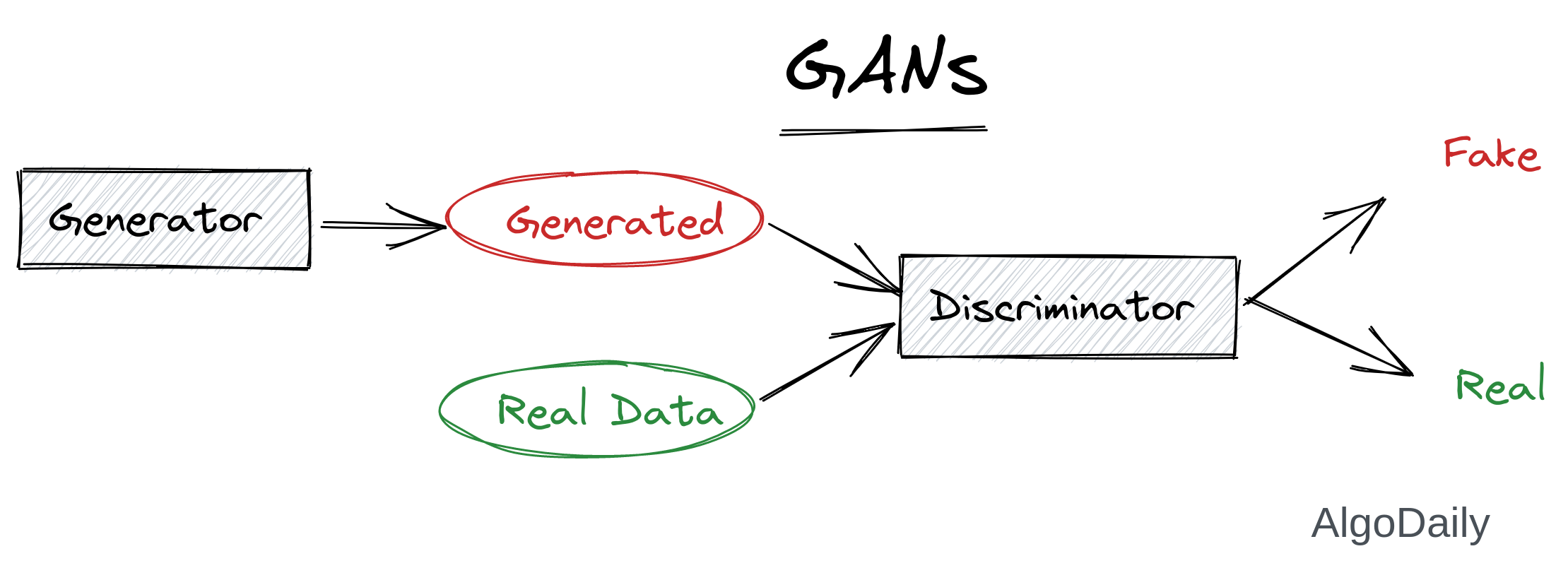
Generative Adversarial Networks (GANs) are one of the most interesting ideas in computer science today. Two models are trained simultaneously by an adversarial process. A generator (“the artist”) learns to create images that look real, while a discriminator (“the art critic”) learns to tell real images apart from fakes.
The main equation upon which the model is built on is given below:
$$min_G max_D (V_{GAN}(D,G) = E_{x ~ P_{data(x)}} [logD(x)] + E_{z~P_z(z)}[log(1-D(G(z)))]$$
To keep it simple, these are the points you need to keep in mind:
- Generator takes a random seed and generates a sample
- Discriminator takes an image and tries to detect if that image is from a specific distribution (from the actual dataset).
- Discriminator is trained on 2 types of images:
- Generator generated image with label 0.
- An image from the dataset with label 1.
GAN is famous for creating AMAZING original photos out of an existing dataset. Below is an image is taken from NVidia, where you can draw anything and it will be transformed into a photorealistic photo of nature.

TensorFlow’s official website has an intuitive guide of how to implement it on TensorFlow. We will follow that guide, but make the code even simpler so you have no problem understanding it. You already understand that we need to design two models for GAN. First, let’s import everything and take the MNIST dataset as an example. GAN is an unsupervised learning model, so we do not need any labels for our data.
Import what we need:
| |
And load the data:
| |
We will create a model where the discriminator will take each image of shape (28,28,1). So the generator has to predict a shape of the same. It can take any size of seed as input, but we will use a linear data of 100 random numbers. Lets reshape and preprocess (simple standardization) the data:
| |
Now define some hyperparameters. We will use these variables throughout the code. The names are all self-explanatory
| |
Convert the dataset into a tensorflow dataset:
| |
To create the generator model we will start with the noise of shape (100,). After a Dense layer, we reshape the model to a 3D shape to match with the image. The height and width will be 7, and the number of channels will be 256. Later we use a layer named transposed convolution, which is basically the opposite of convolution. The rest are almost the same as any other trivial model.
| |
The loss function is the first interesting thing to look at in a GAN. The generator will always be told that its fake inputs are 0 so that it tries to generate better results. The loss of the generator will depend on the output of the discriminator. There will be a lower loss if the discriminator predicts a value close to 1, and 0 otherwise.
For the discriminator, the loss is more straightforward. If the image is from an actual dataset, then the loss is 1. And if the images are coming from the generator, the loss is 0.
Finally, we will use the Adam optimizer with a very small learning rate in the example.
| |
The second interesting part of GAN is its training loop. As there are two networks dependent on each other and will be trained simultaneously, the fit method will not work here. We will need to create a custom training loop. While feed forwarding, we keep track of the gradients of each parameter in a GradientTape (separate for each model). After feed forwarding both models, we apply the gradient of loss to both models’ weights.
Note that the training function will need to be compiled so that TensorFlow can build the computation graph first. This helps to speed up the training process and run the function on different devices.
| |
Now that everything is set, we can run several epochs and provide a batch of images to the train_step function.
| |
Note: This will take hours to train on this simple dataset. This is the downside of GAN for the moment. It takes a tremendous amount of computational resources and time to train two models simultaneously.
After the training, you can see a sample image generated by creating a seed and passing it through the generator model. You can create as many images as you want (passing the batch size to the model).
| |
Now you have an artist model which can draw images like a dataset you provided. Cool, right?
Most advanced Machine Learning model (2021): GPT3
GPT-3 is the newest advanced neural network model developed by (OpenAI)[https://openai.com/] which can generate a whole new level of realistic images, videos, code that works by your logic, websites, story, and many more. It is a very deep neural network with 175 billion training parameters. The model is trained in such a way that it can understand the placement of words in any context. It can have a sense of tense, parts of speech, tokens, and tags in programming/scripting languages and many more.
Although GPT-3 is not that useful right now for programmers because is not fully open-sourced yet. But using the API of GPT-3, you can do a lot of cool stuff like telling the program to create an application and it will write the code for your application. So let us see an example of the usage of GPT-3.
The GPT-3 has three variants of language models that we can use.
- Zero-shot model: You provide no example and the model will try to figure out what the result should be.
- One-shot model: You provide only one example and the model should figure out the result of the next inputs.
- Few-shot model: You provide some examples and the model will figure out what the next results should be.
We will use the Few-shot model and the GPT-3 API provided by OpenAI to create a chatbot.
Note: You will need access to the GPT-3 beta program to use the API. Go ahead and join the beta program and request access here.
First, we create the environment and install the only requirement for our project:
| |
Start the code by importing and creating a Completion instance of the OpenAI language model. This instance is designed to assist you with different kinds of text completion.
| |
As we will follow the few-shot model, we need an example from which we can start the chat. We will pick up a generalized starting point of the chat. You can change this to something else and see what predictions you get. Just try to select a seed point that is long enough for the model to understand what kind of conversation you want. We will also keep a log of all the messages to provide it to GPT-3 so it can get the context of each new message and try to relate the different pronouns we use.
class chatbot():
def __init__(self):
self.first_msg = '''
Human: Hi there, how are you?
AI: I am great. How can I help you today?
Human:
'''
self.log = self.first_msg
def ask(self, question):
pass
Now we need to send the whole log message to concatenate by the new question of human and send that to GPT-3 via the API. The completion object will help us to create a request and send it over the internet. There are a lot of parameters for its create method. Let us see some of them:
- prompt: The input text which needs to be completed
- engine: OpenAI has made four text completion engines available, named davinci, ada, babbage and curie. We are using davinci, which is the most capable of the four.
- temperature: a number between 0 and 1 that determines how many creative risks the engine takes when generating text.
- top_p: an alternative way to control the originality and creativity of the generated text.
- frequency_penalty: a number between 0 and 1. The higher this value the model will make a bigger effort in not repeating itself.
- presence_penalty: a number between 0 and 1. The higher this value the model will make a bigger effort in talking about new topics.
- max_tokens: The maximum completion length.
| |
After sending the response, we need to select the first answer the model gives us. We can return the answer, but before that, we need to update out text log. The final ask function is given below:
| |
To use this class, we can instantiate and ask some questions.
| |
It is awesome, right? Let us know in the discussion section what your conversation with GPT-3 was about.
Conclusion
This lesson was all about making you as much comfortable as possible with a world full of different machine learning models. I hope you will have no problem grabbing a model from the internet, read out its architecture and how it works, and apply it to your own applications.
