Welcome! My name is Vijay Nagarajan, and I am excited to teach this course as this is my area of research. This course presents fundamental principles in computer architecture. You will learn about pipelining, branch prediction, dynamic scheduling, superscalars, caches, virtual memory, shared-memory multiprocessors, memory consistency, cache coherence, hardware support for synchronization, multithreading, SIMD/Vector processing, and GPUs. You will learn some of these concepts (likely branch prediction and prefetching) in depth by implementing them using the Intel Pin dynamic binary instrumentation tool.
Lectures
- MoWe/01:25PM-02:45PM WEB L105
Piazza
- Please sign up as a student at this link: https://piazza.com/utah/fall2023/csece6810
- Please post any question about the course at Piazza first. You are actively encouraged to answer questions too. The TAs and I will be monitoring Piazza.
- Any high-level clarification questions on the assignments are permitted, but please do not post answers!
Material
Teaching Team:
- Instructor: Vijay Nagarajan, email: vijay@cs.utah.edu, Office hours: Friday: 3 pm - 4 pm, WEB 2897 (Happy to discuss anything about the course, or anything related to the area. Questions about the practical assignments should be directed to the TAs.)
- TA: Aditya Gattu, email: u1418754@gcloud.utah.edu, Office hours: Tuesday: 3 pm - 5 pm, CADE Lab (Questions about the practicals and questions about the course welcome.)
- TA: Sharad Bhat, email: u1418984@utah.edu, Office hours: Wednesday: 3 pm - 5 pm, CADE Lab (Questions about the practicals and questions about the course welcome.)
- Grader: An Qi Zhang
Assessment:
- Two practical assignments each worth 20 points, for a total of 40 points.
- Two in-class quizzes, each worth 10 points. The best of the two goes towards the final grade. So total of 10 points.
- One final in-class exam worth 50 points.
- Grading: 100–94: A, 93.9–90: A-, 89.9–87: B+, 86.9–84: B, 83.9 –80: B-, 79.9 –77: C+, 76.9–74: C, 73.9–70: C-, 69.9–67: D+, 66.9–64: D, 63.9–60: D-, 59.9–0: E
Prerequisites:
- You are expected to know introductory computer architecture concepts such as those covered in CS 3810 including instruction set architecture, assembly programming, combinational logic, and sequential logic.
- There will be significant C++ programming in this course. You are expected to be well-versed in C++, or be prepared to pick up C++ programming. Here is a C++ tutorial.
Policies:
- We have zero tolerance for cheating. If your score in the assignments are significantly higher than the scores in the exam, only your score in the exam will count towards your grade.
- For the two practical assignments, you are given a grace period of 24 hours with a penalty of 10 percent of the score in that assignment. Assignments that are submitted more than 24 hours late will get a zero unless there is a serious reason (e.g., medical reason with doctor’s evidence).
- Please read the SoC policy on Academic Misconduct. Discussing high-level ideas behind the practical assignments is permitted and encouraged, but the code you turn in must be your own. You may not copy code from others or the internet, and you may not allow another student to copy your code. Use of tools such as AutoPilot and ChatGPT is not permitted. Any violation of the above is considered cheating and may result in a failing grade. TAs will be on the lookout for code that look similar using an automated tool that is not going to be fooled by changing variable names.
How to do well in this class?
- Attend the lectures. Study the reading material, if any, before the class. (Don’t worry if you don’t fully understand it. ) If there are any problems posted, please attempt to solve them before the lecture.
- Take advantage of office hours and get your questions clarified.
- Please start the practical assignments early. Do not wait till the deadline.
- The exam will test your understanding and problem solving ability and will not test bookwork. So, please ensure you understand the material deeply.
- Think critically about the subject, read up on papers related to the topic, and most importantly, have fun!
| Date | Topic | Before class | Event |
|---|
| M, Aug 21 | Introduction | Read: HP5: 1.1 – 1.6 | |
| W, 23 | Measuring Performance | Read: HP5: 1.8 – end | |
| M, 28 | Measuring Performance/ Instruction set architecture | HP5: Appendix A | |
| W, 30 | Instruction set architecture | Problem-set-1, Read RISC-V manual Chapters 2,6, and 7. How does RISC-V compare to MIPS? | |
| W, Sep 6 | Pipelining | Read C.1, C.2 | |
| M, 11 | Pipelining | | |
| W, 13 | Handling Hazards | Read: HP5: C.3, C.5, 3.3 | |
| M, 18 | Handling Hazards | Problem-set-2 | 1st practical: Out |
| W, 20 | Dynamic Scheduling (Scoreboarding) | Read: HP5: C.7 | |
| M, 25 | Dynamic Scheduling (Tomasulo’s Algorithm) | Read: HP5: 3.4, 3.5 | |
| W, 27 | Tomasulo’s | | |
| M, Oct 2 | Tomasulo’s | | 1st practical: Due |
| W, 4 | Quiz-1/Superscalars | Read: HP5: 3.7 – 3.10 | |
| M, 16 | Superscalars | | |
| W, 18 | Caches | Read: HP5: B.1 | |
| M, 23 | Cache performance | | |
| W, 25 | Cache performance | | 2nd Practical Out |
| M, 30 | Virtual Memory | B.4, 2.6 | |
| W, Nov 1 | Multiprocessors | Primer: 1.1, 1.2, 2, 3 | |
| M, 6 | Snooping Coherence | Primer: 7.1, 7.2 | |
| W, 8 | Directory Coherence | Primer: 8.1, 8.2 | 2nd Practical: Due |
| M, 13 | Directory Coherence | | |
| W, 15 | Memory Consistency | Primer: 3.1, 3.2, 3.3, | |
| M, 20 | Memory Consistency | Primer: 4.1, 5.1 | Problem-set-3 |
| W, 22 | Quiz-2 | | |
| M, 27 | Synchronization | Primer: 3.9, 4.4.1 | |
| W, 29 | Synchronization | | |
| M, Dec 4 | | | |
| W, 6 | | | |
| M, 11 | | | |
| W, 13 | Final exam: 1 pm - 3pm | | Final exam |
Slides
Programming Assignments
PA 1 (PDF)
Implementation Details
Implementation of PHT
Line 107 to 140 is the implementation of the class PHT. The class has an array pointer named table that contains an array of unsigned short representing each pattern history. This class also has a getPrediction method that returns the prediction at the given index. Also it has two convenient function inc and dec to do saturated increment and decrement.
Implementation of LHR
Line 71 to 105 has the implementation of the class LHR. The class has an array pointer named regs that contains an array of array of bool representing local history registers. This class has a shift and get method that shifts the register at a given index and returns the value at the given index correspondingly.
Besides these, line 142 to 148 is a helper function that takes an ADDRINT and returns the nBits LSB of it.
Implementation of Each Branch Predictor
1. Local Branch Predictor
LocalBranchPredictor class is implemented from line 150 to 172. It has a PHT and a LHR as its member variable. It has a getPrediction method that returns the prediction at the given address. It also has a update method that updates the PHT and LHR at the given address with the given outcome.
2. Global Branch Predictor
GshareBranchPredictor class is implemented from line 174 to 208. It has a PHT but no LHR. Instead it maintains a single register named ghr. Like Local Branch Predictor, it also has a getPrediction method that returns the prediction at the given address. It also has a update method that updates the PHT and LHR at the given address with the given outcome.
3. Tournament Branch Predictor
TournamentBranchPredictor class is implemented from line 210 to 244. It has it’s meta PHT, and instance of LocalBranchPredictor and GshareBranchPredictor. It also has a getPrediction method that first gets the prediction from metaPHT and then chooses the predictor, and then gets prediction from it’s members. For the train method, it stores the prediction of both local and global predictor first and then trains them. Finally based on whether it’s prediction for predictor is correct or not, it trains the metaPHT accordingly.
Question Answers
Q. Why and how varying the size of the PHT impacts (or not) the prediction accuracy for each of the predictors?
The larger the size of PHT, the larger the size of the indexing of the PHT has to be. Hence the larger the size of LHR or GHR will be. So LHR or GHR will be able to remember more history. Hence the prediction accuracy will be higher.
Q. What are the advantages and disadvantages of the Local predictor?
Advantages: This is simplest of all the predictors. It works well for programs that does not have nested loops.
Disadvantages: It does not work well for programs that have nested loops. For it’s simplicity, it does not have a good prediction accuracy for general programs and cannot capture control hazards that depend on other branches.
Q. What are the advantages and disadvantages of the Gshare predictor?
Advantages: It works well for programs that have nested loops. It has a better prediction accuracy than local predictor for general programs. It only requires a single register to store the global history instead of multiple registers in local predictor.
Disadvantages: It works a little worse than tournament predictor for general programs. Same register will be used too frequently for all the branch instructions in the program, leading to latency in some cases.
Q. What benefits did you expect from the addition of the Tournament predictor? Did the results match your expectations?
I expected the tournament predictor to have a better prediction accuracy than both local and gshare predictor and results matched my expectations.
Also I expected tournament predictor to be the slowest of all the predictors and it was the slowest of all the predictors.
Finally, I predicted that having more number of PHT entries will increase the prediction accuracy even more compared to local and gshare predictor. As I saw in the benchmark results, local branch predictor kind of saturates after having more than 1024 PHT entries (noticable in GOBMK benchmark). Gshare branch predictor also saturates similarly (noticable in Matrix Multiplication benchmark). But tournament predictor does not saturate even after having 4096 PHT entries (noticable in all the benchmarks). So my this expectation also matched with the result.
GOBMK and Sjeng benchmark programs behaved very similarly. Among these two, GOBMK was the hardest one for branch prediction. As GOBMK has a lot of nested loops, local branch predictor did a very bad job compared to other predictors. For both gshare and tournament predictor, I found that they need an even more number of entries in the PHT for higher accuracy (at the cost of hardware for bigger PHTs).
Finally the Matrix-multiplication was the simplest program among these three. For this program, I think ~99.6% is the optimal performance any predictor can do, so all three predictors saturated at the accuracy with very few (1024) number of entries.
Benchmark Results
Here are the three benchmark results for each of the predictors.
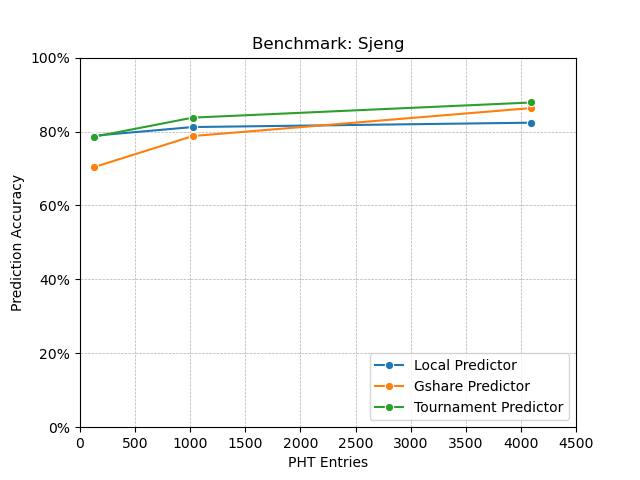
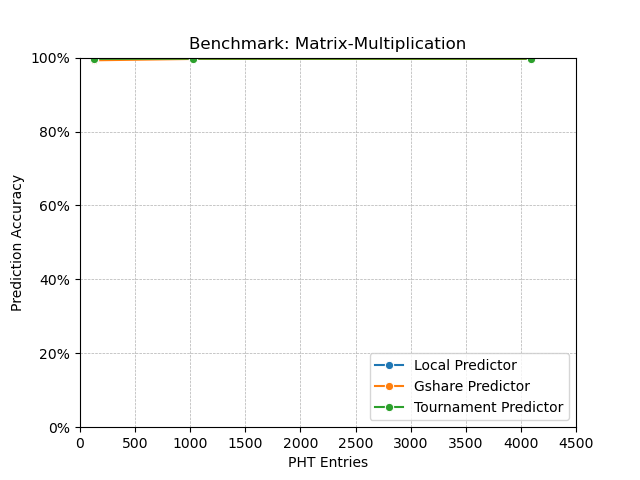
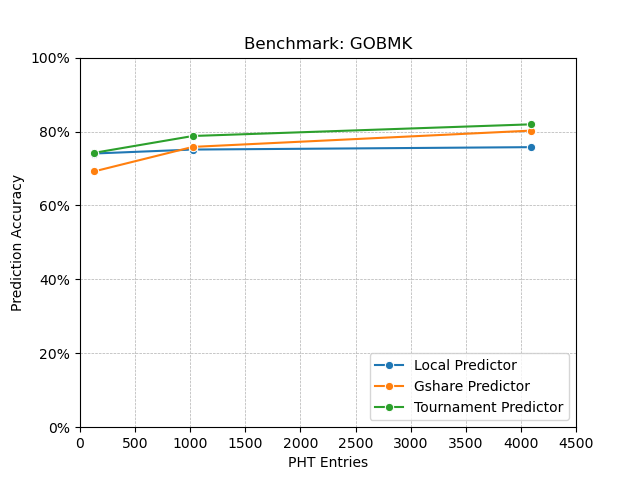
I find it a little difficult for the y axis limits being from 0 to 100 (especially for the Matrix Multiplication benchmark). So I have also included the same graphs with better y axis limits. Also I make the x axis in log scale.
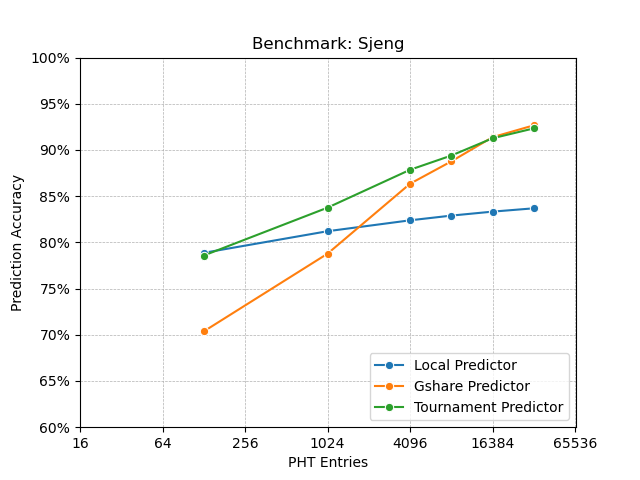
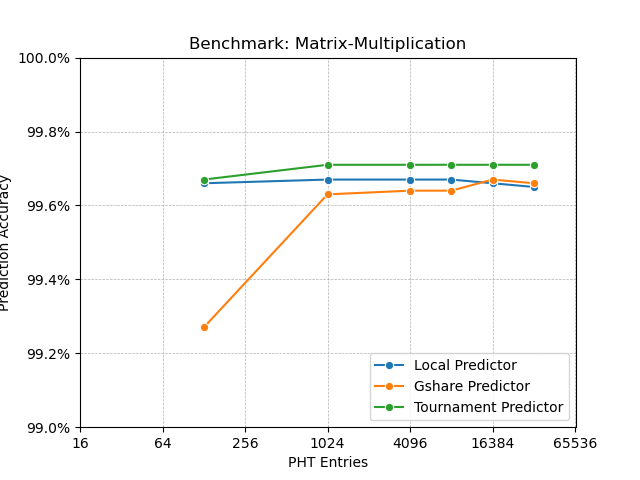
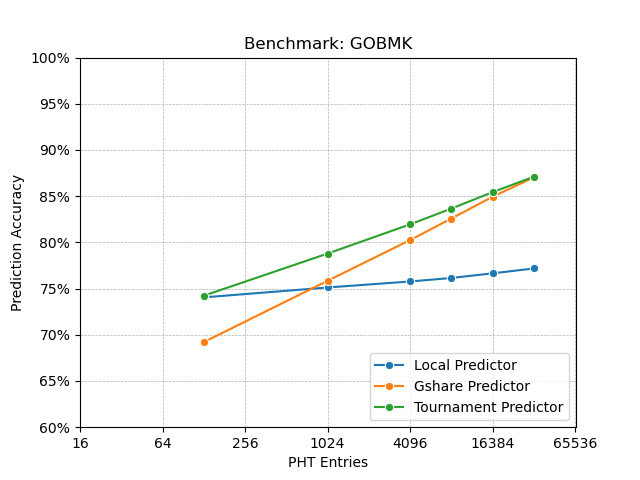
Appendix
Code for plotting
The python program used to generate the plots right from the result file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
cache_sizes = [128, 1024, 4096]
bps = [
"Local Predictor",
"Gshare Predictor",
"Tournament Predictor",
]
prob_line_start = {
'Sjeng': 0,
'GOBMK': 10,
'Matrix-Multiplication': 20,
}
with open('results') as f:
all_lines = f.readlines()
for prob_line_name, prob_line in prob_line_start.items():
lines = all_lines[prob_line:prob_line+9]
vals = list(map(lambda x: round(float(x.strip().split()[4])*100, 2), lines))
for i, bp in enumerate(bps):
y_vals = vals[i*3:(i+1)*3]
print(y_vals)
sns.lineplot(x=cache_sizes, y=y_vals, label=bp, marker='o')
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.xlabel("PHT Entries")
# plt.xscale("log", base=2)
locs, _ = plt.xticks()
labels = [str(int(loc)) for loc in locs]
plt.xticks(ticks=locs, labels=labels)
plt.ylim(0, 100)
# if prob_line_name == 'Sjeng' or prob_line_name == 'GOBMK':
# # plt.ylim(60, 100)
# else:
# plt.ylim(99, 100)
locs, labels = plt.yticks()
labels = [label.get_text() + '%' for label in labels]
plt.yticks(ticks=locs, labels=labels)
plt.ylabel("Prediction Accuracy")
plt.title("Benchmark: " + prob_line_name)
plt.legend(loc="lower right")
plt.xlim(0, 4500)
# plt.savefig(prob_line_name + "-corr.png")
plt.savefig(prob_line_name + ".png")
plt.close()
|
My Makefile
I also used this Makefile to run the benchmarks in a single command. Note: I ran it on my local machine instead of CADE and pin was in PATH on my machine. (Also ran it on Cade afterwards to make sure it compiles)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| PIN=pin
BP=obj-intel64/branch_predictor_example.so
BP_PATH=BPExample
TARGET_PLATFORM=intel64
# BENCHMARK=car_asn1_files/benchmarks/458.sjeng/run_base_ref_amd64-m64-gcc41-nn.0000/sjeng_base.amd64-m64-gcc41-nn
# BENCHMARK_REF=car_asn1_files/benchmarks/458.sjeng/run_base_ref_amd64-m64-gcc41-nn.0000/ref.txt
# BENCHMARK=car_asn1_files/benchmarks/matrix_multiplication.exe
# BENCHMARK_REF=
BENCHMARK=car_asn1_files/benchmarks/445.gobmk/run_base_ref_amd64-m64-gcc41-nn.0000/gobmk_base.amd64-m64-gcc41-nn
BENCHMARK_REF=--quiet < car_asn1_files/benchmarks/445.gobmk/run_base_ref_amd64-m64-gcc41-nn.0000/13x13.tst -o 13x13.out
BP: $(BP_PATH)/branch_predictor_example.cpp
mkdir -p $(BP_PATH)/obj-intel64
make -C $(BP_PATH) $(BP) TARGET=$(TARGET_PLATFORM)
always.out: BP
$(PIN) -t $(BP_PATH)/$(BP) -BP_type always_taken -num_BP_entries 128 -o stats_always-128.out -- $(BENCHMARK) $(BENCHMARK_REF) > always-128.out
$(PIN) -t $(BP_PATH)/$(BP) -BP_type always_taken -num_BP_entries 1024 -o stats_always-1024.out -- $(BENCHMARK) $(BENCHMARK_REF) > always-1024.out
$(PIN) -t $(BP_PATH)/$(BP) -BP_type always_taken -num_BP_entries 4096 -o stats_always-4096.out -- $(BENCHMARK) $(BENCHMARK_REF) > always-4096.out
local.out: BP
$(PIN) -t $(BP_PATH)/$(BP) -BP_type local -num_BP_entries 128 -o stats_local-128.out -- $(BENCHMARK) $(BENCHMARK_REF) > local-128.out
$(PIN) -t $(BP_PATH)/$(BP) -BP_type local -num_BP_entries 1024 -o stats_local-1024.out -- $(BENCHMARK) $(BENCHMARK_REF) > local-1024.out
$(PIN) -t $(BP_PATH)/$(BP) -BP_type local -num_BP_entries 4096 -o stats_local-4096.out -- $(BENCHMARK) $(BENCHMARK_REF) > local-4096.out
gshare.out: BP
$(PIN) -t $(BP_PATH)/$(BP) -BP_type gshare -num_BP_entries 128 -o stats_gshare-128.out -- $(BENCHMARK) $(BENCHMARK_REF) > gshare-128.out
$(PIN) -t $(BP_PATH)/$(BP) -BP_type gshare -num_BP_entries 1024 -o stats_gshare-1024.out -- $(BENCHMARK) $(BENCHMARK_REF) > gshare-1024.out
$(PIN) -t $(BP_PATH)/$(BP) -BP_type gshare -num_BP_entries 4096 -o stats_gshare-4096.out -- $(BENCHMARK) $(BENCHMARK_REF) > gshare-4096.out
tournament.out: BP
$(PIN) -t $(BP_PATH)/$(BP) -BP_type tournament -num_BP_entries 128 -o stats_tournament-128.out -- $(BENCHMARK) $(BENCHMARK_REF) > tournament-128.out
$(PIN) -t $(BP_PATH)/$(BP) -BP_type tournament -num_BP_entries 1024 -o stats_tournament-1024.out -- $(BENCHMARK) $(BENCHMARK_REF) > tournament-1024.out
$(PIN) -t $(BP_PATH)/$(BP) -BP_type tournament -num_BP_entries 4096 -o stats_tournament-4096.out -- $(BENCHMARK) $(BENCHMARK_REF) > tournament-4096.out
all: always.out local.out gshare.out tournament.out
clean:
make -C $(BP_PATH) clean
rm -f *.out
rm -f *.log
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
| #include <cstdint>
#include <iostream>
#include <fstream>
#include <cstdlib>
#include<cmath>
#include "pin.H"
using std::cerr;
using std::endl;
using std::ios;
using std::ofstream;
using std::string;
// Simulation will stop when this number of instructions have been executed
//
#define STOP_INSTR_NUM 1000000000 // 1b instrs
// Simulator heartbeat rate
//
#define SIMULATOR_HEARTBEAT_INSTR_NUM 100000000 // 100m instrs
/* Base branch predictor class */
// You are highly recommended to follow this design when implementing your branch predictors
//
class BranchPredictorInterface {
public:
//This function returns a prediction for a branch instruction with address branchPC
virtual bool getPrediction(ADDRINT branchPC) = 0;
//This function updates branch predictor's history with outcome of branch instruction with address branchPC
virtual void train(ADDRINT branchPC, bool branchWasTaken) = 0;
};
// This is a class which implements always taken branch predictor
class AlwaysTakenBranchPredictor : public BranchPredictorInterface {
public:
AlwaysTakenBranchPredictor(UINT64 numberOfEntries) {}; //no entries here: always taken branch predictor is the simplest predictor
virtual bool getPrediction(ADDRINT branchPC) {
return true; // predict taken
}
virtual void train(ADDRINT branchPC, bool branchWasTaken) {} //nothing to do here: always taken branch predictor does not have history
};
//------------------------------------------------------------------------------
//##############################################################################
/*
* Insert your changes below here...
*
* Put your branch predictor implementation here
*
* For example:
* class LocalBranchPredictor : public BranchPredictorInterface {
*
* ***put private members for Local branch predictor here
*
* public:
* virtual bool getPrediction(ADDRINT branchPC) {
* ***put your implementation here
* }
* virtual void train(ADDRINT branchPC, bool branchWasTaken) {
* ***put your implementation here
* }
* }
*
* You also need to create an object of branch predictor class in main()
* (i.e. at line 193 in the original unmodified version of this file).
*/
//##############################################################################
//------------------------------------------------------------------------------
// This class is the implementation of a local history register.
class LHR {
// there are 128 registers of size nBits
bool *regs[128];
unsigned long nBits; // size of each register
public:
LHR(UINT64 numberOfEntries) {
// If numberOfEntries is zero, then the number of entries in the branch predictor is not valid
if(numberOfEntries <= 0) {
std::cerr << "Error: number of entries in branch predictor must be positive." << std::endl;
std::exit(EXIT_FAILURE);
}
// nBits is the number of bits in each register
nBits = std::log10(numberOfEntries) / std::log10(2);
// initialize the registers with 0
// default value of bool is false
for (auto i = u_long(0); i < 128; i++)
regs[i] = new bool[nBits];
}
// shift the register at index to the left and add newBit to the right
void shift(int index, int newBit) {
for (auto i = u_long(0); i < nBits - 1; i++)
regs[index][i] = regs[index][i + 1];
regs[index][nBits - 1] = newBit;
}
// get the value of the register at index
u_long get(int index) {
auto result = u_long(0);
for (auto i = u_long(0); i < nBits; i++)
result |= regs[index][i] << i;
return result;
}
};
// This class is the implementation of a pattern history table.
// Instead of having only 2-bit registers, you can use this class to have n-bit registers.
class PHT {
unsigned short *table;
unsigned long nBits;
public:
PHT(UINT64 numberOfEntries, int nBits): nBits(nBits) {
if(numberOfEntries <= 0) {
std::cerr << "Error: number of entries in branch predictor must be positive." << std::endl;
std::exit(EXIT_FAILURE);
}
// initialize the table with all 1s
table = new unsigned short[numberOfEntries];
for (auto i = u_long(0); i < numberOfEntries; i++)
table[i] = std::pow(2, nBits) - 1;
}
// get the prediction for the branch instruction at index
bool getPrediction(unsigned long idx) {
return table[idx] >= std::pow(2, nBits - 1);
}
// increment or decrement the register at index
void inc(unsigned long index) {
if (table[index] < std::pow(2, nBits) - 1)
table[index]++;
}
void dec(unsigned long index) {
if (table[index] > 0)
table[index]--;
}
};
// get the first n bits of branchPC
unsigned long getFirstNBits(ADDRINT branchPC, unsigned long nBits) {
unsigned long mask = 0;
for (auto i = u_long(0); i < nBits; i++)
mask += std::pow(2, i);
return branchPC & mask;
}
class LocalBranchPredictor : public BranchPredictorInterface {
LHR lhr;
PHT pht;
public:
LocalBranchPredictor(UINT64 numberOfEntries): lhr(numberOfEntries), pht(numberOfEntries, 2) {}
// we get the first 7 bits of PC, and use it as the index of the LHR, and then use the value of the LHR as the index of the PHT
bool getPrediction(ADDRINT branchPC) {
return pht.getPrediction(
lhr.get(
getFirstNBits(branchPC, 7)
)
);
}
void train(ADDRINT branchPC, bool branchWasTaken) {
auto index = getFirstNBits(branchPC, 7);
auto phtIndex = lhr.get(index);
// strengthen or weaken the pht
branchWasTaken ? pht.inc(phtIndex) : pht.dec(phtIndex);
// update the lhr for next prediction
lhr.shift(index, branchWasTaken);
}
};
class GshareBranchPredictor : public BranchPredictorInterface {
// gshare only has one global history register of nBits bits
bool *ghr;
unsigned long nBits;
PHT pht;
// get the first nBits bits of branchPC XORed with the value of ghr
unsigned long getPHTIndex(ADDRINT branchPC) {
auto ghrInt = u_long(0);
for (auto i = u_long(0); i < nBits; i++)
ghrInt += ghr[i] * std::pow(2, i);
return getFirstNBits(branchPC, nBits) ^ ghrInt;
}
public:
GshareBranchPredictor(UINT64 numberOfEntries): pht(numberOfEntries, 2) {
nBits = std::log10(numberOfEntries) / std::log10(2);
ghr = new bool[nBits];
};
// Just using the private method to the PHT index from branchPC and then get the prediction
bool getPrediction(ADDRINT branchPC) {
return pht.getPrediction(
getPHTIndex(branchPC)
);
}
void train(ADDRINT branchPC, bool branchWasTaken) {
auto index = getPHTIndex(branchPC);
// strengthen or weaken the pht
branchWasTaken ? pht.inc(index) : pht.dec(index);
// shift ghr
for (auto i = u_long(0); i < nBits - 1; i++)
ghr[i] = ghr[i + 1];
// add new bit to ghr right
ghr[nBits - 1] = branchWasTaken;
}
};
class TournamentBranchPredictor : public BranchPredictorInterface {
PHT metaPHT;
LocalBranchPredictor localBP;
GshareBranchPredictor gshareBP;
unsigned long nBits;
public:
TournamentBranchPredictor(UINT64 numberOfEntries): metaPHT(numberOfEntries, 2), localBP(numberOfEntries), gshareBP(numberOfEntries) {
nBits = std::log10(numberOfEntries) / std::log10(2);
};
// Here first we get the prediction from the metaPHT, and then use the prediction to get the prediction from either localBP or gshareBP
bool getPrediction(ADDRINT branchPC) {
return metaPHT.getPrediction(
getFirstNBits(branchPC, nBits)
) ? gshareBP.getPrediction(branchPC) : localBP.getPrediction(branchPC);
}
void train(ADDRINT branchPC, bool branchWasTaken) {
auto index = getFirstNBits(branchPC, nBits);
auto metaPred = metaPHT.getPrediction(index);
auto localPred = localBP.getPrediction(branchPC);
auto gsharePred = gshareBP.getPrediction(branchPC);
// strengthen or weaken both local and gshare
localBP.train(branchPC, branchWasTaken);
gshareBP.train(branchPC, branchWasTaken);
// if metaPred is correct
if(!metaPred && localPred == branchWasTaken)
metaPHT.dec(index);
else if (metaPred && gsharePred == branchWasTaken)
metaPHT.inc(index);
// otherwise
if (!metaPred && gsharePred == branchWasTaken)
metaPHT.inc(index);
else if (metaPred && localPred == branchWasTaken)
metaPHT.dec(index);
}
};
ofstream OutFile;
BranchPredictorInterface *branchPredictor;
// Define the command line arguments that Pin should accept for this tool
//
KNOB<string> KnobOutputFile(KNOB_MODE_WRITEONCE, "pintool",
"o", "BP_stats.out", "specify output file name");
KNOB<UINT64> KnobNumberOfEntriesInBranchPredictor(KNOB_MODE_WRITEONCE, "pintool",
"num_BP_entries", "1024", "specify number of entries in a branch predictor");
KNOB<string> KnobBranchPredictorType(KNOB_MODE_WRITEONCE, "pintool",
"BP_type", "always_taken", "specify type of branch predictor to be used");
// The running counts of branches, predictions and instructions are kept here
//
static UINT64 iCount = 0;
static UINT64 correctPredictionCount = 0;
static UINT64 conditionalBranchesCount = 0;
static UINT64 takenBranchesCount = 0;
static UINT64 notTakenBranchesCount = 0;
static UINT64 predictedTakenBranchesCount = 0;
static UINT64 predictedNotTakenBranchesCount = 0;
VOID docount() {
// Update instruction counter
iCount++;
// Print this message every SIMULATOR_HEARTBEAT_INSTR_NUM executed
if (iCount % SIMULATOR_HEARTBEAT_INSTR_NUM == 0) {
std::cerr << "Executed " << iCount << " instructions." << endl;
}
// Release control of application if STOP_INSTR_NUM instructions have been executed
if (iCount == STOP_INSTR_NUM) {
PIN_Detach();
}
}
VOID TerminateSimulationHandler(VOID *v) {
OutFile.setf(ios::showbase);
// At the end of a simulation, print counters to a file
OutFile << "Prediction accuracy:\t" << (double)correctPredictionCount / (double)conditionalBranchesCount << endl
<< "Number of conditional branches:\t" << conditionalBranchesCount << endl
<< "Number of correct predictions:\t" << correctPredictionCount << endl
<< "Number of taken branches:\t" << takenBranchesCount << endl
<< "Number of non-taken branches:\t" << notTakenBranchesCount << endl
;
OutFile.close();
std::cerr << endl << "PIN has been detached at iCount = " << STOP_INSTR_NUM << endl;
std::cerr << endl << "Simulation has reached its target point. Terminate simulation." << endl;
std::cerr << "Prediction accuracy:\t" << (double)correctPredictionCount / (double)conditionalBranchesCount << endl;
std::exit(EXIT_SUCCESS);
}
//
VOID Fini(int code, VOID * v)
{
TerminateSimulationHandler(v);
}
// This function is called before every conditional branch is executed
//
static VOID AtConditionalBranch(ADDRINT branchPC, BOOL branchWasTaken) {
/*
* This is the place where the predictor is queried for a prediction and trained
*/
// Step 1: make a prediction for the current branch PC
//
bool wasPredictedTaken = branchPredictor->getPrediction(branchPC);
// Step 2: train the predictor by passing it the actual branch outcome
//
branchPredictor->train(branchPC, branchWasTaken);
// Count the number of conditional branches executed
conditionalBranchesCount++;
// Count the number of conditional branches predicted taken and not-taken
if (wasPredictedTaken) {
predictedTakenBranchesCount++;
} else {
predictedNotTakenBranchesCount++;
}
// Count the number of conditional branches actually taken and not-taken
if (branchWasTaken) {
takenBranchesCount++;
} else {
notTakenBranchesCount++;
}
// Count the number of correct predictions
if (wasPredictedTaken == branchWasTaken)
correctPredictionCount++;
}
// Pin calls this function every time a new instruction is encountered
// Its purpose is to instrument the benchmark binary so that when
// instructions are executed there is a callback to count the number of
// executed instructions, and a callback for every conditional branch
// instruction that calls our branch prediction simulator (with the PC
// value and the branch outcome).
//
VOID Instruction(INS ins, VOID *v) {
// Insert a call before every instruction that simply counts instructions executed
INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR)docount, IARG_END);
// Insert a call before every conditional branch
if ( INS_IsBranch(ins) && INS_HasFallThrough(ins) ) {
INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR)AtConditionalBranch, IARG_INST_PTR, IARG_BRANCH_TAKEN, IARG_END);
}
}
// Print Help Message
INT32 Usage() {
cerr << "This tool simulates different types of branch predictors" << endl;
cerr << endl << KNOB_BASE::StringKnobSummary() << endl;
return -1;
}
int main(int argc, char * argv[]) {
// Initialize pin
if (PIN_Init(argc, argv)) return Usage();
// Create a branch predictor object of requested type
if (KnobBranchPredictorType.Value() == "always_taken") {
std::cerr << "Using always taken BP" << std::endl;
branchPredictor = new AlwaysTakenBranchPredictor(KnobNumberOfEntriesInBranchPredictor.Value());
}
//------------------------------------------------------------------------------
//##############################################################################
/*
* Insert your changes below here...
*
* In the following cascading if-statements instantiate branch predictor objects
* using the classes that you have implemented for each of the three types of
* predictor.
*
* The choice of predictor, and the number of entries in its prediction table
* can be obtained from the command line arguments of this Pin tool using:
*
* KnobNumberOfEntriesInBranchPredictor.Value()
* returns the integer value specified by tool option "-num_BP_entries".
*
* KnobBranchPredictorType.Value()
* returns the value specified by tool option "-BP_type".
* The argument of tool option "-BP_type" must be one of the strings:
* "always_taken", "local", "gshare", "tournament"
*
* Please DO NOT CHANGE these strings - they will be used for testing your code
*/
//##############################################################################
//------------------------------------------------------------------------------
else if (KnobBranchPredictorType.Value() == "local") {
std::cerr << "Using Local BP." << std::endl;
/* Uncomment when you have implemented a Local branch predictor */
branchPredictor = new LocalBranchPredictor(KnobNumberOfEntriesInBranchPredictor.Value());
}
else if (KnobBranchPredictorType.Value() == "gshare") {
std::cerr << "Using Gshare BP."<< std::endl;
/* Uncomment when you have implemented a Gshare branch predictor */
branchPredictor = new GshareBranchPredictor(KnobNumberOfEntriesInBranchPredictor.Value());
}
else if (KnobBranchPredictorType.Value() == "tournament") {
std::cerr << "Using Tournament BP." << std::endl;
/* Uncomment when you have implemented a Tournament branch predictor */
branchPredictor = new TournamentBranchPredictor(KnobNumberOfEntriesInBranchPredictor.Value());
}
else {
std::cerr << "Error: No such type of branch predictor. Simulation will be terminated." << std::endl;
std::exit(EXIT_FAILURE);
}
std::cerr << "The simulation will run " << STOP_INSTR_NUM << " instructions." << std::endl;
OutFile.open(KnobOutputFile.Value().c_str());
// Pin calls Instruction() when encountering each new instruction executed
INS_AddInstrumentFunction(Instruction, 0);
// Function to be called if the program finishes before it completes 10b instructions
PIN_AddFiniFunction(Fini, 0);
// Callback functions to invoke before Pin releases control of the application
PIN_AddDetachFunction(TerminateSimulationHandler, 0);
// Start the benchmark program. This call never returns...
PIN_StartProgram();
return 0;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| Sjeng local 128 : 0.788741
Sjeng local 1024 : 0.812107
Sjeng local 4096 : 0.823909
Sjeng gshare 128 : 0.703676
Sjeng gshare 1024 : 0.787845
Sjeng gshare 4096 : 0.863479
Sjeng Tournament 128 : 0.785817
Sjeng Tournament 1024 : 0.83761
Sjeng Tournament 4096 : 0.878563
Gobmk local 128 : 0.740518
Gobmk local 1024 : 0.751152
Gobmk local 4096 : 0.757742
Gobmk gshare 128 : 0.692081
Gobmk gshare 1024 : 0.758448
Gobmk gshare 4096 : 0.802452
Gobmk Tournament 128 : 0.742259
Gobmk Tournament 1024 : 0.787875
Gobmk Tournament 4096 : 0.819516
Matrix_Mul local 128 : 0.996622
Matrix_Mul local 1024 : 0.996742
Matrix_Mul local 4096 : 0.996729
Matrix_Mul gshare 128 : 0.992749
Matrix_Mul gshare 1024 : 0.996342
Matrix_Mul gshare 4096 : 0.996446
Matrix_Mul Tournament 128 : 0.99672
Matrix_Mul Tournament 1024 : 0.997134
Matrix_Mul Tournament 4096 : 0.997139
|
PA 2 (PDF)
Solution Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
|
#include "pin.H"
#include <stdlib.h>
#include <random>
#include "dcache_for_prefetcher.hpp"
#include "pin_profile.H"
class PrefetcherInterface {
public:
virtual void prefetch(ADDRINT addr, ADDRINT loadPC) = 0;
virtual void train(ADDRINT addr, ADDRINT loadPC) = 0;
};
PrefetcherInterface *prefetcher;
ofstream outFile;
Cache *cache;
UINT64 loads;
UINT64 stores;
UINT64 hits;
UINT64 accesses, prefetches;
string prefetcherName;
int sets;
int associativity;
int blockSize;
UINT64 checkpoint = 100000000;
UINT64 endpoint = 2000000000;
/* ===================================================================== */
/* Commandline Switches */
/* ===================================================================== */
KNOB<string> KnobPrefetcherName(KNOB_MODE_WRITEONCE, "pintool",
"pref_type","none", "prefetcher name");
KNOB<UINT32> KnobAggression(KNOB_MODE_WRITEONCE, "pintool",
"aggr", "2", "the aggression of the prefetcher");
KNOB<string> KnobOutputFile(KNOB_MODE_WRITEONCE, "pintool",
"o", "data", "specify output file name");
KNOB<UINT32> KnobCacheSets(KNOB_MODE_WRITEONCE, "pintool",
"sets", "64", "cache size in kilobytes");
KNOB<UINT32> KnobLineSize(KNOB_MODE_WRITEONCE, "pintool",
"b", "4", "cache block size in bytes");
KNOB<UINT32> KnobAssociativity(KNOB_MODE_WRITEONCE, "pintool",
"a", "2", "cache associativity (1 for direct mapped)");
/* ===================================================================== */
// Print a message explaining all options if invalid options are given
INT32 Usage()
{
cerr << "This tool represents a cache simulator." << endl;
cerr << KNOB_BASE::StringKnobSummary() << endl;
return -1;
}
// Take checkpoints with stats in the output file
void takeCheckPoint()
{
outFile << "The checkpoint has been reached" << endl;
outFile << "Accesses: " << accesses << " Loads: "<< loads << " Stores: " << stores << endl;
outFile << "Hits: " << hits << endl;
outFile << "Hit rate: " << double(hits) / double(accesses) << endl;
outFile << "Prefetches: " << prefetches << endl;
outFile << "Successful prefetches: " << cache->getSuccessfulPrefs() << endl;
if (accesses == endpoint) exit(0);
}
/* ===================================================================== */
/* None Prefetcher
This does not prefetch anything.
*/
class NonePrefetcher : public PrefetcherInterface {
public:
void prefetch(ADDRINT addr, ADDRINT loadPC) {
return;
}
void train(ADDRINT addr, ADDRINT loadPC) {
return;
}
};
/* ===================================================================== */
/* Next Line Prefetcher
This is an example implementation of the next line Prefetcher.
The stride prefetcher would also need the program counter of the load instruction.
*/
class NextNLinePrefetcher : public PrefetcherInterface {
public:
void prefetch(ADDRINT addr, ADDRINT loadPC) {
for (int i = 1; i <= aggression; i++) {
UINT64 nextAddr = addr + i * blockSize;
if (!cache->exists(nextAddr)) { // Use the member function Cache::exists(UINT64) to query whether a block exists in the cache w/o triggering any LRU changes (not after a demand access)
cache->prefetchFillLine(nextAddr); // Use the member function Cache::prefetchFillLine(UINT64) when you fill the cache in the LRU way for prefetch accesses
prefetches++;
}
}
}
void train(ADDRINT addr, ADDRINT loadPC) {
return;
}
};
//---------------------------------------------------------------------
//##############################################
/*
* Your changes here.
*
* Put your prefetcher implementation here
*
* Example:
*
* class StridePrefetcher : public PrefetcherInterface {
* private:
* // set up private members
*
* public:
* void prefetch(ADDRINT addr, ADDRINT loadPC) {
* // Prefetcher implementation
* }
*
* void train(ADDRINT addr, ADDRINT loadPC) {
* // Training implementation
* }
* };
*
* You can modify the functions Load() and Store() where necessary to implement your functionality
*
* DIRECTIONS ON USING THE COMMAND LINE ARGUMENT
* The string variable "prefetcherName" indicates the name of the prefetcher that is passed as a command line argument (-pref_type)
* The integer variable "aggression" indicates the aggressiveness indicated by the command line argument (-aggr)
*
* STATS:
* ***Note that these exist to help you debug your program and produce your graphs
* The member function Cache::getSuccessfulPrefs() returns how many of the prefetched block into the cache were actually used. This applies in the case where no prefetch buffer is used.
* The integer variable "prefetches" should count the number of prefetched blocks
* The integer variable "accesses" counts the number of memory accesses performed by the program
* The integer variable "hits" counts the number of memory accesses that actually hit in either the data cache or the prefetch buffer such that hits = cacheHits + prefHits
*
*/
//##############################################
//---------------------------------------------------------------------
// Returns a random number between 0 and a-1
int getRandomNumber(unsigned int a) {
std::random_device rd;
std::mt19937 gen(rd());
// Create a uniform integer distribution from 0 to a-1
std::uniform_int_distribution<> dis(0, a-1);
// Generate and return the random number
return dis(gen);
}
// The states from the state diagram of the stride prefetcher
enum StrideRPTState {
INITIAL = 0,
TRANSIENT = 1,
STEADY = 2,
NO_PREDICTION = 3
};
// A single entry in the RPT
class StrideRPTEntry {
public:
ADDRINT tag;
ADDRINT prevAddr;
int stride;
StrideRPTState state;
StrideRPTEntry(): tag(0), prevAddr(0), stride(0), state(StrideRPTState::INITIAL) {}
};
// The RPT of stride prefetcher
class StrideRPT {
public:
StrideRPTEntry *entries;
unsigned long numEntries;
// This tracks which of the entries are initialized
// This just adds some optimization to the code
bool* initialized;
StrideRPT(const int numEntries): numEntries(numEntries) {
entries = new StrideRPTEntry[numEntries];
initialized = new bool[numEntries];
for(int i = 0; i < numEntries; i++) {
initialized[i] = false;
}
}
// Adds a new entry to RPT according to the random replacement policy
void addNewEntry(const ADDRINT tag, const ADDRINT prevAddr) {
auto non_initialized = find(initialized, initialized + numEntries, false);
if(non_initialized == initialized + numEntries) {
// If all entries are initialized
int index = getRandomNumber(numEntries);
entries[index].tag = tag;
entries[index].stride = 0;
entries[index].state = StrideRPTState::INITIAL;
entries[index].prevAddr = prevAddr;
}
else {
// If some entries are not initialized
int index = non_initialized - initialized;
entries[index].tag = tag;
entries[index].stride = 0;
entries[index].state = StrideRPTState::INITIAL;
entries[index].prevAddr = prevAddr;
initialized[index] = true;
}
}
// Returns the entry corresponding to the tag
StrideRPTEntry* getEntry(const ADDRINT tag) {
auto entryPtr = find_if(entries, entries + numEntries, [&tag](const StrideRPTEntry &e) { return e.tag == tag; });
if (entryPtr == entries + numEntries) {
return nullptr;
}
return entryPtr;
}
};
// Simulate the state diagram of the stride prefetcher
StrideRPTState updateRPTStateCorrect(StrideRPTState state) {
switch (state) {
case StrideRPTState::INITIAL:
return StrideRPTState::STEADY;
case StrideRPTState::TRANSIENT:
return StrideRPTState::STEADY;
case StrideRPTState::STEADY:
return StrideRPTState::STEADY;
case StrideRPTState::NO_PREDICTION:
return StrideRPTState::TRANSIENT;
default:
return StrideRPTState::INITIAL;
}
}
// Simulate the state diagram of the stride prefetcher
StrideRPTState updateRPTStateIncorrect(StrideRPTState state) {
switch (state) {
case StrideRPTState::INITIAL:
return StrideRPTState::TRANSIENT;
case StrideRPTState::TRANSIENT:
return StrideRPTState::NO_PREDICTION;
case StrideRPTState::STEADY:
return StrideRPTState::INITIAL;
case StrideRPTState::NO_PREDICTION:
return StrideRPTState::NO_PREDICTION;
default:
return StrideRPTState::INITIAL;
}
}
class StridePrefetcher : public PrefetcherInterface {
private:
int aggressiveness;
StrideRPT rpt;
public:
StridePrefetcher(const int aggressiveness, unsigned long entries): aggressiveness(aggressiveness), rpt(entries) {}
void prefetch(ADDRINT addr, ADDRINT loadPC) {
auto rptEntry = rpt.getEntry(loadPC);
if(rptEntry == nullptr) return;
if(rptEntry->prevAddr + rptEntry->stride == addr) {
// if pred is correct
if(rptEntry->state == StrideRPTState::STEADY) {
auto prefetched_addr = addr;
for(int i = 1; i <= aggressiveness; i++) {
prefetched_addr = addr + rptEntry->stride * i;
if(!cache->exists(prefetched_addr)) {
cache->prefetchFillLine(prefetched_addr);
prefetches++;
}
}
rptEntry->prevAddr = prefetched_addr;
}
else {
rptEntry->prevAddr = addr;
}
rptEntry->state = updateRPTStateCorrect(rptEntry->state);
}
else {
// if pred is wrong
if(rptEntry->state != StrideRPTState::STEADY) {
rptEntry->stride = addr - rptEntry->prevAddr;
}
rptEntry->state = updateRPTStateIncorrect(rptEntry->state);
rptEntry->prevAddr = addr;
}
}
void train(ADDRINT addr, ADDRINT loadPC) {
auto rptEntry = rpt.getEntry(loadPC);
if(rptEntry == nullptr) {
rpt.addNewEntry(loadPC, addr);
}
}
};
class DistanceRPTEntry {
public:
signed long tag;
signed long *distance;
unsigned int numDistances;
DistanceRPTEntry(long tag, unsigned int numDistances): tag(tag), numDistances(numDistances) {
distance = new long[numDistances];
for(unsigned int i = 0; i < numDistances; i++) {
distance[i] = 0;
}
}
~DistanceRPTEntry() {
delete[] distance;
}
void addDistance(const long dist) {
auto non_initialized = find(distance, distance + numDistances, 0);
if(non_initialized == distance + numDistances) {
// If all entries are initialized
int index = getRandomNumber(numDistances);
distance[index] = dist;
}
else {
// If some entries are not initialized
int index = non_initialized - distance;
distance[index] = dist;
}
}
};
class DistanceRPT {
public:
DistanceRPTEntry *entries;
unsigned long numEntries;
unsigned long numDistances;
bool *initialized;
// This distance RPT is generalized for any number of entries and any number of distances
DistanceRPT(const unsigned long numEntries, const unsigned long numDistances): numEntries(numEntries), numDistances(numDistances) {
entries = static_cast<DistanceRPTEntry*>(operator new[](numEntries * sizeof(DistanceRPTEntry)));
initialized = new bool[numEntries];
for(unsigned long i = 0; i < numEntries; i++) {
initialized[i] = false;
new(&entries[i]) DistanceRPTEntry(0, numDistances);
}
}
~DistanceRPT() {
delete[] initialized;
for(unsigned long i = 0; i < numEntries; i++) {
entries[i].~DistanceRPTEntry();
}
operator delete[](entries);
}
// Adds new entry according to the random replacement policy
DistanceRPTEntry* addNewEntry(const long dist) {
auto non_initialized = find(initialized, initialized + numEntries, false);
if(non_initialized == initialized + numEntries) {
// If all entries are initialized
int index = getRandomNumber(numEntries);
entries[index].tag = dist;
for(unsigned long i = 0; i < numDistances; i++) {
entries[index].distance[i] = 0;
}
return entries + index;
}
else {
// If some entries are not initialized
int index = non_initialized - initialized;
entries[index].~DistanceRPTEntry();
new(&entries[index]) DistanceRPTEntry(dist, numDistances);
initialized[index] = true;
return entries + index;
}
}
// Returns the entry corresponding to the tag
DistanceRPTEntry* getEntry(const long tag) {
auto entryPtr = find_if(entries, entries + numEntries, [&tag](const DistanceRPTEntry &e) { return e.tag == tag; });
if (entryPtr == entries + numEntries) {
return nullptr;
}
return entryPtr;
}
};
class DistancePrefetcher : public PrefetcherInterface {
private:
unsigned long numEntries;
unsigned long numDistances;
DistanceRPT rpt;
ADDRINT prevAddr;
long prevDist;
public:
DistancePrefetcher(const unsigned long aggressiveness, const unsigned long numEntries): numEntries(numEntries), numDistances(aggressiveness), rpt(numEntries, aggressiveness), prevAddr(0), prevDist(0) {}
void prefetch(ADDRINT addr, ADDRINT loadPC) {
if(prevAddr == 0) {
prevAddr = addr;
return;
}
long dist = ((long)addr - (long)prevAddr);
auto rptEntry = rpt.getEntry(dist);
if(rptEntry == nullptr) {
// If rpt is miss
rpt.addNewEntry(dist);
}
else {
// if rpt is hit
for (unsigned long i = 0; i < numDistances; i++) {
if (rptEntry->distance[i] != 0) {
auto prefetched_addr = addr + rptEntry->distance[i];
if (!cache->exists(prefetched_addr)) {
cache->prefetchFillLine(prefetched_addr);
prefetches++;
}
}
}
}
}
void train(ADDRINT addr, ADDRINT loadPC) {
// Training implementation
auto rptEntry = rpt.getEntry(prevDist);
if(rptEntry == nullptr) {
rptEntry = rpt.addNewEntry(prevDist);
}
signed long newDist = ((long)addr - (long)prevAddr);
rptEntry->addDistance(newDist);
prevDist = newDist;
prevAddr = addr;
}
};
/* ===================================================================== */
/* Action taken on a load. Load takes 2 arguments:
addr: the address of the demanded block (in bytes)
pc: the program counter of the load instruction
*/
void Load(ADDRINT addr, ADDRINT pc)
{
accesses++;
loads++;
if (cache->probeTag(addr)) { // Use the function Cache::probeTag(UINT64) when you are probing the cache after a demand access
hits++;
}
else {
cache->fillLine(addr); // Use the member function Cache::fillLine(addr) when you fill in the MRU way for demand accesses
prefetcher->prefetch(addr, pc);
prefetcher->train(addr, pc);
}
if (accesses % checkpoint == 0) takeCheckPoint();
}
/* ===================================================================== */
//Action taken on a store
void Store(ADDRINT addr, ADDRINT pc)
{
accesses++;
stores++;
if (cache->probeTag(addr)) hits++;
else cache->fillLine(addr);
if (accesses % checkpoint == 0) takeCheckPoint();
}
/* ===================================================================== */
// Receives all instructions and takes action if the instruction is a load or a store
// DO NOT MODIFY THIS FUNCTION
void Instruction(INS ins, void * v)
{
if (INS_IsMemoryRead(ins) && INS_IsStandardMemop(ins)) {
INS_InsertPredicatedCall(
ins, IPOINT_BEFORE, (AFUNPTR) Load,
(IARG_MEMORYREAD_EA), IARG_INST_PTR, IARG_END);
}
if ( INS_IsMemoryWrite(ins) && INS_IsStandardMemop(ins))
{
INS_InsertPredicatedCall(
ins, IPOINT_BEFORE, (AFUNPTR) Store,
(IARG_MEMORYWRITE_EA), IARG_INST_PTR, IARG_END);
}
}
/* ===================================================================== */
// Gets called when the program finishes execution
void Fini(int code, VOID * v)
{
outFile << "The program has completed execution" << endl;
takeCheckPoint();
cout << double(hits) / double(accesses) << endl;
outFile.close();
}
/* ===================================================================== */
/* Main */
/* ===================================================================== */
int main(int argc, char *argv[])
{
PIN_InitSymbols();
if( PIN_Init(argc,argv) )
{
return Usage();
}
// Initialize stats
hits = 0;
accesses = 0;
prefetches = 0;
loads = 0;
stores = 0;
aggression = KnobAggression.Value();
sets = KnobCacheSets.Value();
associativity = KnobAssociativity.Value();
blockSize = KnobLineSize.Value();
prefetcherName = KnobPrefetcherName;
if (prefetcherName == "none") {
prefetcher = new NonePrefetcher();
} else if (prefetcherName == "next_n_lines") {
prefetcher = new NextNLinePrefetcher();
} else if (prefetcherName == "stride") {
// Uncomment when you implement the stride prefetcher
prefetcher = new StridePrefetcher(aggression, 64);
} else if (prefetcherName == "distance") {
// Uncomment when you implement the distance prefetcher
prefetcher = new DistancePrefetcher(aggression, 64);
} else {
std::cerr << "Error: No such type of prefetcher. Simulation will be terminated." << std::endl;
std::exit(EXIT_FAILURE);
}
// create a data cache
cache = new Cache(sets, associativity, blockSize);
outFile.open(KnobOutputFile.Value());
INS_AddInstrumentFunction(Instruction, 0);
PIN_AddFiniFunction(Fini, 0);
// Never returns
PIN_StartProgram();
return 0;
}
/* ===================================================================== */
/* eof */
/* ===================================================================== */
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| Benchmark1 Stride 1: 0.756934
Benchmark1 Stride 3: 0.768855
Benchmark1 Stride 10: 0.623999
Benchmark1 Distance 1: 0.767119
Benchmark1 Distance 3: 0.815763
Benchmark1 Distance 10: 0.836971
Benchmark2 Stride 1: 0.693055
Benchmark2 Stride 3: 0.725872
Benchmark2 Stride 10: 0.724311
Benchmark2 Distance 1: 0.76798
Benchmark2 Distance 3: 0.801601
Benchmark2 Distance 10: 0.79966
Benchmark3 Stride 1: 0.763073
Benchmark3 Stride 3: 0.761434
Benchmark3 Stride 10: 0.634916
Benchmark3 Distance 1: 0.770956
Benchmark3 Distance 3: 0.81665
Benchmark3 Distance 10: 0.837684
Note:
- The columns are benchmark name, prefetcher name, aggression value.
- Do not edit this file, except to add your numbers.
|
Question Answers
Q. What are the advantages and disadvantages of the Next-N-Line prefetcher?
Advantages: Next-N-Line prefetcher are simple to implement as they only require a single counter to keep track of the number of lines to prefetch. They are also very effective in sequential prefetching as they prefetch the next N lines in the cache line.
Disadvantages: Next-N-Line prefetchers are very ineffective for non-sequential access patterns. For example, if you are accessing only a single member variable of an array of objects, the Next-N-Line prefetcher will prefetch the entire cache line for the array, which is a waste of memory bandwidth. Also for this same reason, for higher aggressiveness it will prefetch many cache lines that will never be used, polluting the cache by evicting useful cache lines. I found the lowest accuracy for Next-N-Line prefetcher.
Q. What are the advantages and disadvantages of the Stride prefetcher?
Advantages: Stride prefetching is effective when there is a constant stride between the memory accesses. For example, the above case where accessing a single variable from array of objects will be very effective with stride prefetcher. It also pollutes lesser than Next-N-Line prefetcher as it only prefetches that it is certain will be used by checking the stride is correct or not and maintaining steady state.
Disadvantages: I find stride prefetcher to be most complex to implement. Also, for non-sequential access patterns (e.g. 1, 5, 2, 6, 3, 7 …), it is not effective as it will not be able to detect any fixed stride and will not prefetch anything.
Q. What are the advantages and disadvantages of the Distance prefetcher?
Advantages: Distance prefetch is good for both Temporal and Spatial locality. It is very effective for non-sequential access patterns as it prefetches the next line that is accessed after a certain number of cycles. It is also very effective for sequential access patterns just like Stride prefetcher. I found the highest accuracy for Distance prefetcher.
Disadvantages: Distance prefetcher uses the biggest RPT table among these 3 prefetchers. This is because it stores several distances for each entry in the RPT table. This makes it more complex to implement and also requires more memory. Also, I found distance prefetcher to be the slowest among these 3 prefetchers.
Q. Why and how, varying aggressiveness impacts (or not) the hit ratio?
I ran all the benchmarks with 1-20 aggression values and tried to find the sweet spot.
Next-N-Line: Simple array accesses will get benefit from higher aggressiveness. But for non-sequential access patterns, higher aggressiveness will pollute the cache a lot. This will decrease the hit ratio. Best aggression value is 1.
Stride: Higher aggressiveness was bad for all microbenchmarks I ran. I think this is because the stride prefetcher is not able to detect the stride correctly for higher aggressiveness. This results in a lot of cache pollution and hence lower hit ratio. Best aggression value is 2-3.
Distance: Higher aggressiveness was good for all microbenchmarks I ran. This is because distance prefetcher is taking advantage of both next-n-line prefetcher and stride prefetcher. Most of the time, it is only using on distance value for each load instruction, except very few instructions where is is using 2 distances for each RPT entry. This results in lesser cache pollution and hence higher hit ratio. Best aggression value is 7-15.
Q. Which prefetcher would you choose and why?
I would choose Distance prefetcher because it is the most effective prefetcher among these 3 prefetchers for all microbenchmarks. Even for microbenchmark2, where random access of array is happening, distance prefetcher maintained a good hit ratio. I also find it very easy to implement compared to stride prefetcher. Also the number of prefetches was lower than other prefetchers, polluting less.